



The Power to Create Video-Based Apps, Fast: How the Coactive Multimodal AI Platform Turns Months Into Minutes


The Coactive engineering team is excited to reveal the latest version of the Coactive Multimodal AI Platform (MAP), the Autumn ‘25 edition. Building apps based on video and image content, such as ad targeting or content personalization apps, is extremely difficult without a platform like Coactive’s. We are enthusiastic about how this latest version makes it even easier for development teams to create business value for their companies. If you’re building targeted advertising workflows, personalized content workflows, content moderation, or other content operations or marketing workflows, this latest version of MAP will make your work faster and easier, while also saving you money in long-term processing costs.
Impact of the updated Coactive Multimodal AI Platform
Working closely with our customers, we have seen how having a video and image AI platform can deliver real business results.
- Closing new business - One major media company closed a $500,000 advertising deal with a major luxury brand, based on the ability to prove that they had the right portfolio of video content, using Coactive
- Reducing costs and time by cutting workflow steps by 50% - At a major brand experience agency, Coactive reduced their content workflow steps by half, saving 6 hours each time the process was run.
The technical performance of the platform provides the speed, scale, and rapid time to value that enterprise customers require:
- Hundreds of millions of vectors hosted today: 200 million, with search latency under one second on this index.
- High volume ingestion throughput in scale testing: 2,000 hours of video prepared in one hour, after which our cloud provider ran out of available spot instances.
- Highly scalable model serving: Coactive ran internal tests and saw 30x the throughput at which a hyperscaler would have rate limited processing. This means that even if you are processing massive content volumes, Coactive can still handle your needs. Coactive can ingest in weeks what competitors can only ingest in months.
- Rapid time to value: customers with repositories measured in millions of video hours went from raw content to search and validated classification in under one hour using Dynamic Tags and Auto Evaluator capabilities.
What’s new in the Autumn ‘25 Release
The Coactive product management and engineering teams have been working closely with our customers in media, entertainment, and retail to ensure that this latest release addresses the pain points that enterprises experience when they are building content workflows and apps.
Highlights of this release
This release contains a lot of updates, and we’ll be doing a blog series to cover the broad range of new capabilities, including how Coactive reimagined the platform, so that users have far greater ability to isolate out and combine visual, audio, and text signals, for much finer-grained control. Highlights of the release include:
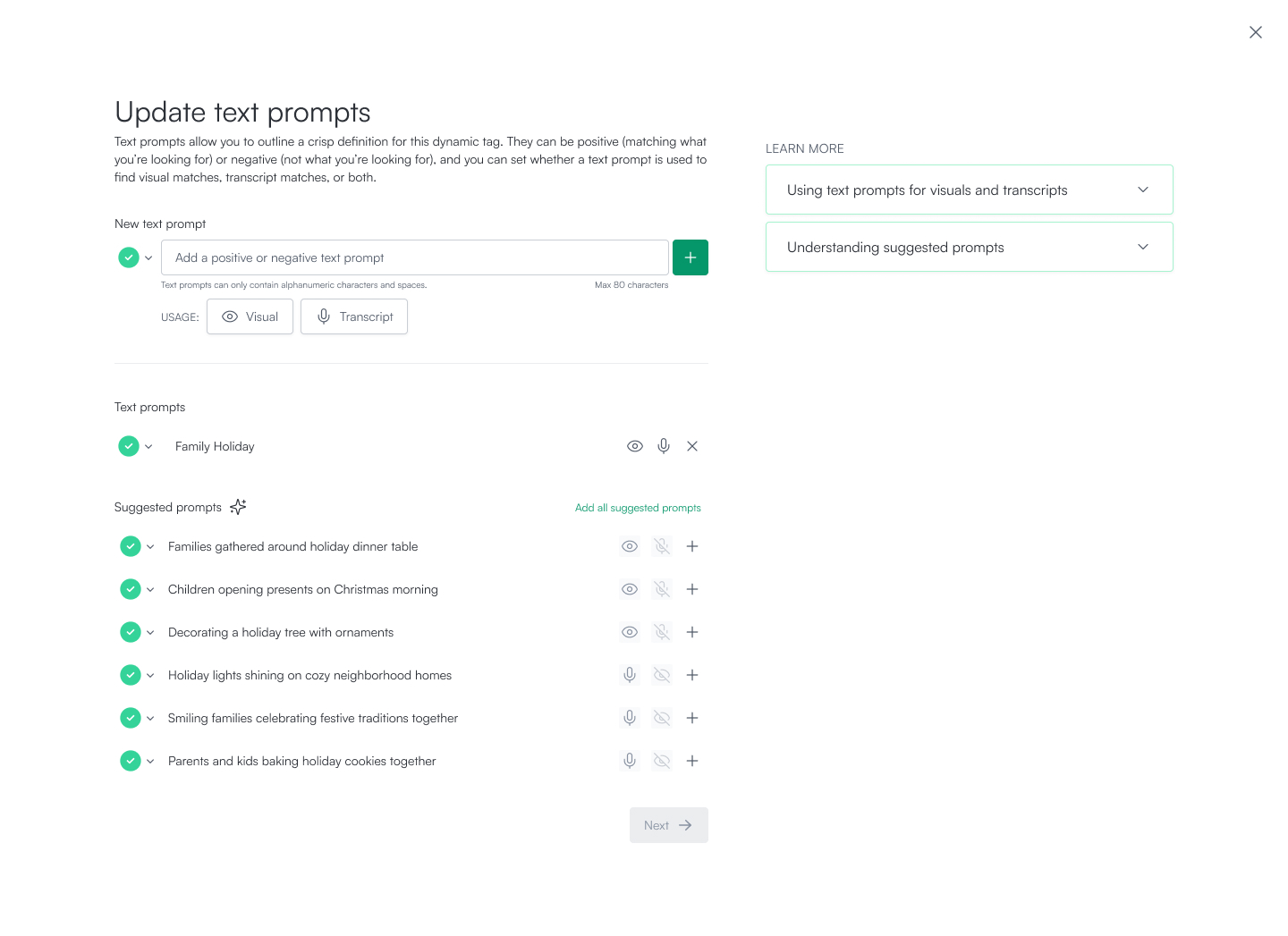
- Smarter tagging with user intent and multimodal signals. Coactive enables users to guide classification with simple text and visual prompts, applying their intent directly to the multimodal embeddings. By combining what’s seen and what’s said with additional signals like mood, emotion, and tone, the platform produces richer, more nuanced tag definitions. Unlike other approaches, Coactive uniquely empowers users to translate subjective ideas and themes into scalable, high-accuracy tagging across vast content libraries.
- Search and tagging at the keyframe, shot, scene, and video level. Customers wanted the ability to easily move back and forth from individual images to complete videos. Coactive not only made this possible with this release, but also made it easier for users to quickly understand and refine those results.
- Tag once, apply multiple times - avoid high reprocessing costs. With the latest release, you can train small, and then go wide. You can apply dynamic tagging to a small training set, even under 5,000 assets, and then apply it to a larger dataset. By leveraging this shared taxonomy, you can save significant time. Also by leveraging the same embeddings that power search, you can enable many tag sets without incurring exponential reprocessing costs.
- Get rapid confidence in tagging results with Auto Evaluator. Generating ground truth is one of the most painful and time-consuming tasks for developers and users. Curating from libraries of thousands or even millions of assets is necessary to measure classification quality, but it slows iteration dramatically. Coactive saw an opportunity in this challenge and built Auto Evaluator, which automatically curates test sets from your own library and delivers immediate precision, recall, and F1. By removing manual effort and offering recommended thresholds out of the box, Auto Evaluator compresses weeks of evaluation work into minutes.
- VIP search and tagging, stay ahead of what’s new. New celebrities, products, and cultural moments emerge every day. An unknown athlete might suddenly become a sensation, or a startup product could become globally popular overnight. For enterprises, this creates a challenge: foundation models are always constrained by their training cutoff, and waiting for retraining isn’t practical. Even if foundation models eventually catch up, reprocessing massive content libraries is prohibitively expensive. Coactive solves this by enabling enterprises to quickly identify new people, products, and places by name, alias, or concept. We built an agent that continuously discovers and trains new concepts such as emerging celebrities, trending products, or newly relevant places directly from customer content libraries.This rapid adaptation flows seamlessly across search, metadata, and classification—so that your systems stay as current as the world around them.
- Quickly leverage the best models for your task. Whether you want to use a state-of-the-art multimodal model or select the best-in-class model for each individual modality and fuse them for higher quality results, Coactive makes it simple. The platform gives you seamless access to a broad portfolio of open and proprietary foundation models through Bedrock, Azure AI Foundry, or Databricks, all unified under a single platform.
Major updates to core platform capabilities
You are already aware that Coactive has powerful capabilities for video and image search, automated metadata tagging, and multimodal analysis. I also wanted to call out how some of these core capabilities have been updated with this release and how that makes a difference to our customers.
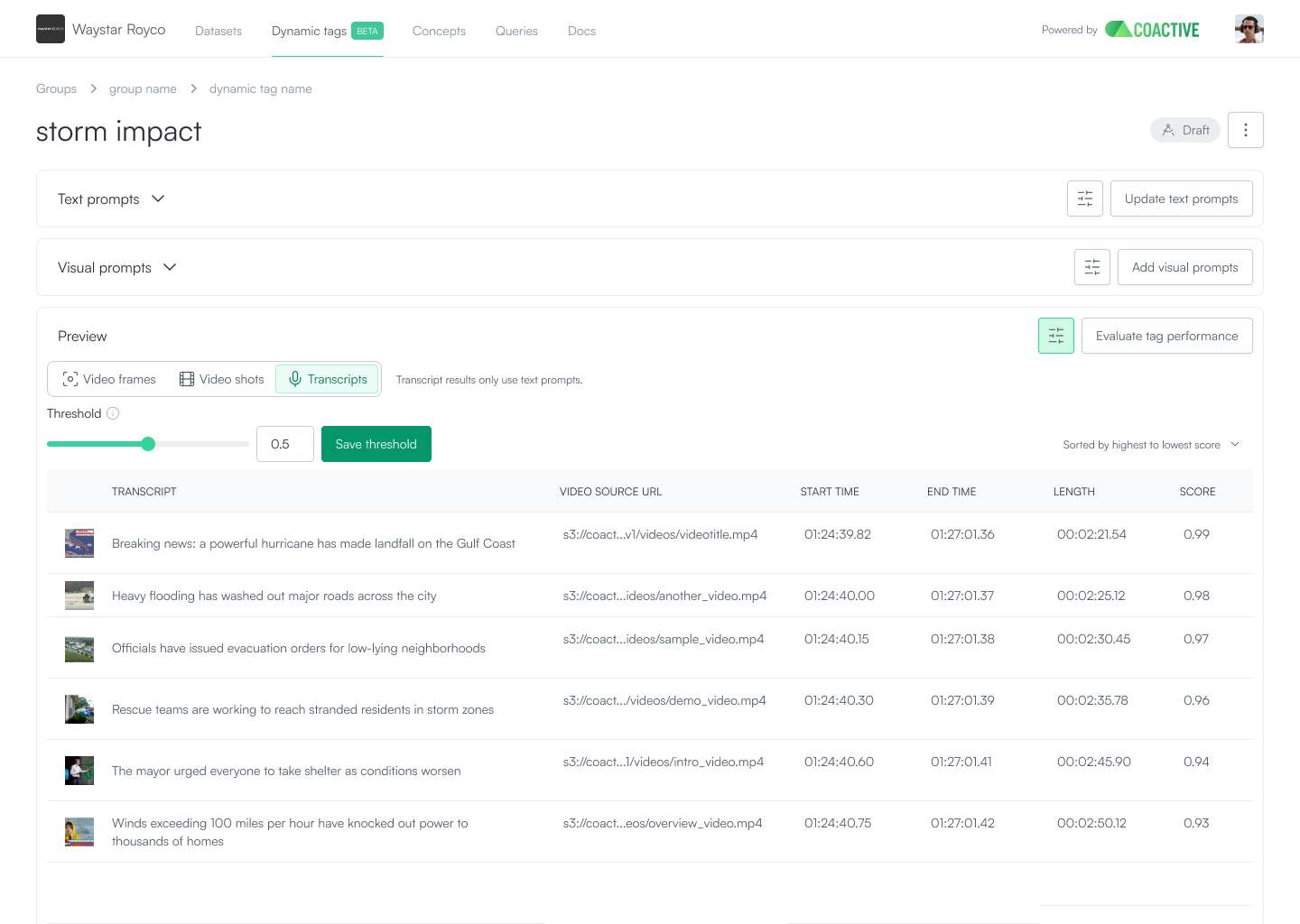
Dynamic Tags: automated tagging with speed, cost savings, and sophistication
Coactive eliminates the trade-off between scale and nuance. The same embeddings that power search also drive classification and metadata generation. Dynamic Tags uses Coactive classification algorithms to label millions of images or millions of minutes of video in a matter of minutes. By reusing embeddings, customers get powerful results, quickly, without having to incur reprocessing costs.
What makes Coactive’s approach unique is its sophistication in handling ambiguous or subjective tagging. Since users can make requests as either or both text and visual prompts, subjective or custom labeling is easier and more effective than alternative approaches.
For example, one media customer asked for content labeled as “Hispanic.” However, this could refer to a wide variety of things: language, on‑screen characters, target audience, or production origin. Using both text and visual prompts, users can easily steer the classifier to their exact meaning, then set thresholds and decision boundaries directly. Data scientists can optimize for precision, recall, and F1 to match downstream needs.
And when your organization’s definition of a term like “Hispanic” changes, Coactive is able to help you adapt quickly and at low cost. Since embeddings can be leveraged again, you avoid reprocessing your data every time the business invents a new taxonomy.
Auto Evaluator: test data sets in minutes, not weeks
Creating ground truth is one of the biggest bottlenecks in AI workflows. Manually curating evaluation data can slow iteration to a crawl, often taking weeks of effort or expensive vendor cycles.
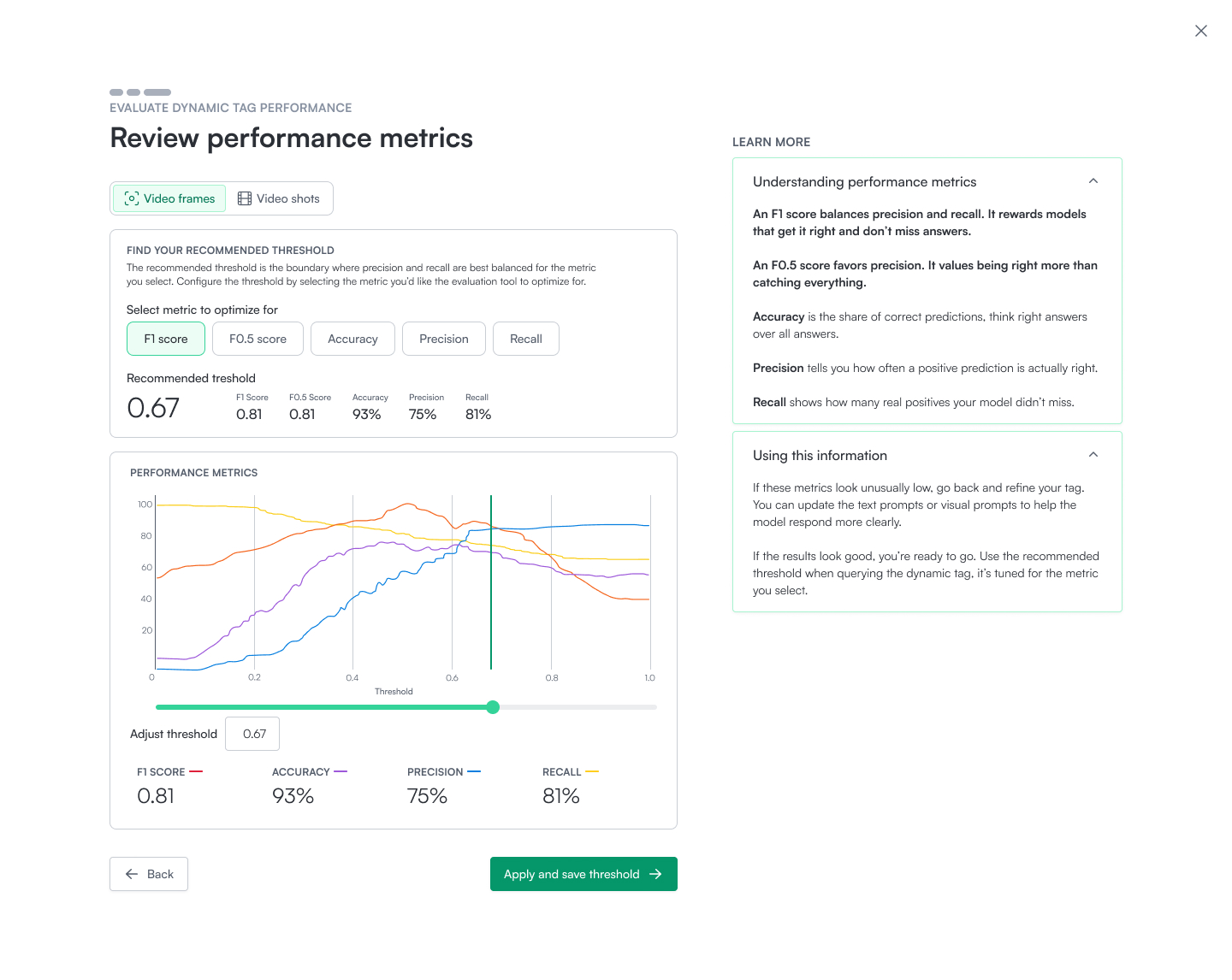
Coactive’s Auto Evaluator removes this pain by using a combination of LLMs and chained vision/audio models to automatically propose labeled test sets from your own corpus. Users can quickly review and refine, then instantly compute precision, recall, and F1 with no heavy lifting required.
With Auto Evaluator, teams move from idea to validation in minutes instead of weeks, dramatically accelerating iteration speed and reducing the cost of experimentation.
Multimodal AI Platform Power and Efficiency
Coactive AI takes the pain out of developing video and image-based apps by providing a single platform for ingestion, foundation model access, embeddings, search, classification, metadata generation, evaluation, and rapid adaptation. Customers can move from raw, untagged content to validated classifiers and search in under an hour, even at large scale. And because one set of embeddings powers many tasks, teams avoid costly reprocessing and achieve far lower total cost of ownership than with traditional approaches, since you don’t have to run separate point systems repeatedly. It’s a far easier path for development teams to use Coactive to build apps quickly than to pick a single foundation model and try to build out all of the other critical elements yourself.
What does this mean to you?
- Developers: Drive faster iteration, experience fewer infrastructure headaches, and get easy integration.
- Engineering Managers: Achieve faster app delivery, while lowering cost and reducing workflow complexity.
- Directors and Executives: Open up new revenue opportunities, achieve strategic agility, and gain a competitive edge from your content.
What does this mean in practice? Developers have already built agentic apps for multimodal search in a single day on Coactive, something that would normally take months of data engineering and MLops.
Pick the platform route - save time, money, and team sanity
Scale, performance, speed of development, and flexibility set Coactive apart. Whether you choose proprietary models such as Gemini or best‑in‑class open models, Coactive makes it simple to start, easy to evolve, and economical to grow. If you want a live walkthrough on your own content, reach out and we will set you up.
Watch the Coactive MAP overview webinar: Sign up now.
Check out our documentation: Coactive AI Documentation.
Get in touch with an expert about your use case. Reach a multimodal AI expert.


