



MediaPerf Results for New NVIDIA Nemotron 3 Nano Omni Pushing the Efficiency Pareto Frontier


Every multimodal model launch comes with an accuracy chart. And for good reason, as benchmarks like Video-MMMU and MMLU have been essential for tracking progress in model quality. But if you’re a technical leader deploying video AI at catalog scale, you already know that accuracy is only one variable in the deployment equation.
The questions that actually gate production deployments are about efficiency: How fast can you process tens of thousands of hours of video? What does it cost per hour at scale? And critically, how do those numbers trade off against each other?
These are the questions MediaPerf was designed to answer. MediaPerf is an open benchmark for AI video understanding in the media industry. It evaluates multimodal foundation models on real media data and tasks, and it reports quality, cost, and latency together, because in production, you can’t optimize for just one.
Today, we’re excited to share results from the latest submission to MediaPerf: NVIDIA Nemotron 3 Nano Omni.
The results
MediaPerf v.2026.02 evaluates models across three tasks that represent core media AI workloads: video-level tagging, video summarization, and a five-round tag refinement workload that simulates iterative taxonomy development (the kind of work media and ad tech teams actually do when building custom content taxonomies).
On the tagging task, Nemotron 3 Nano Omni delivered the most striking result in this benchmark cycle: highest throughput (9.91 hours of video processed per hour) and lowest inference cost ($14.27) across every benchmarked model, open and closed-source. This is the Pareto-optimal corner: best speed and best cost efficiency on the same task. Nemotron 3 Nano Omni is pushing the Pareto frontier on media workloads across both open and closed-source models, on the task where cost efficiency matters most.
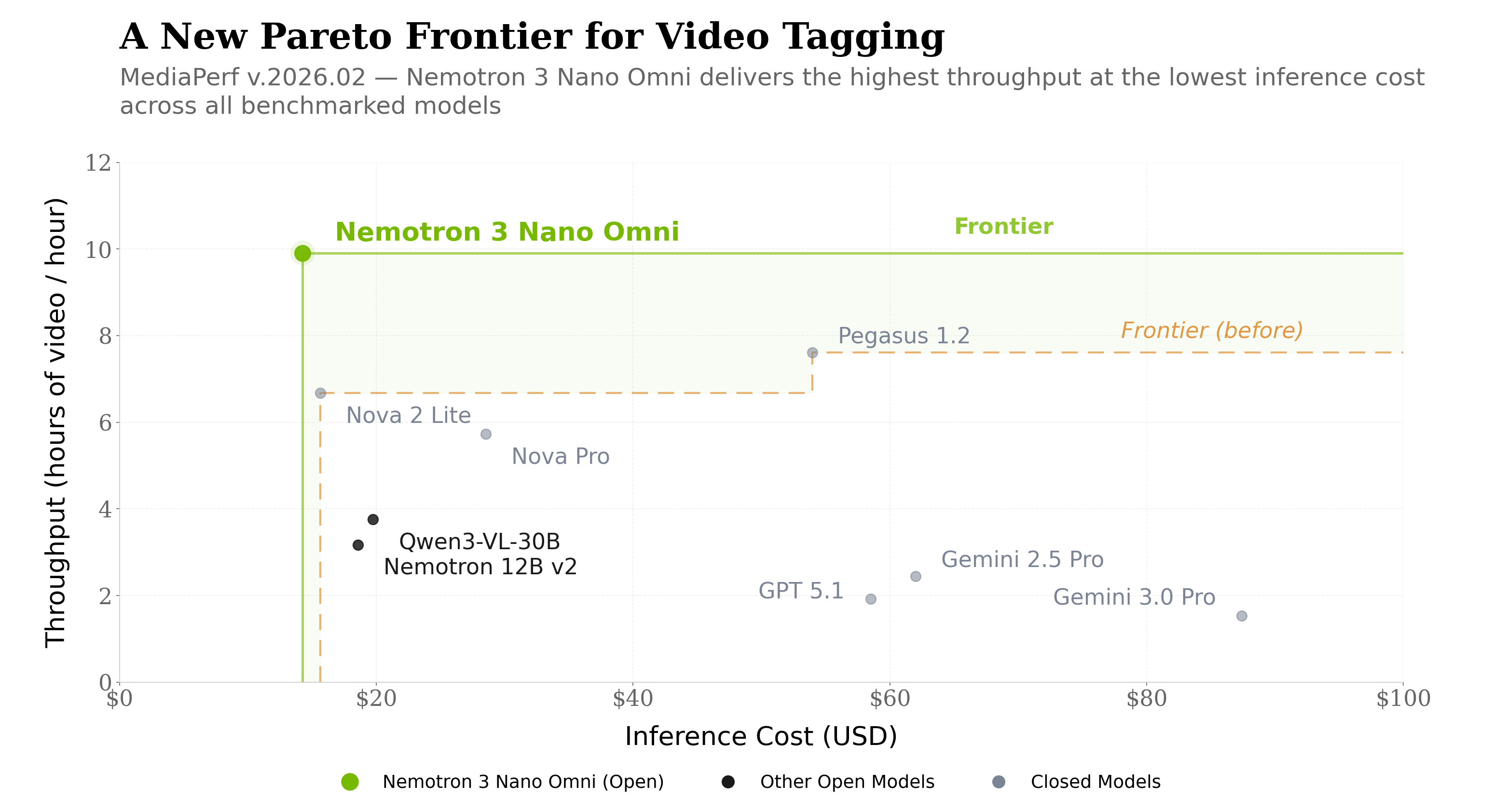
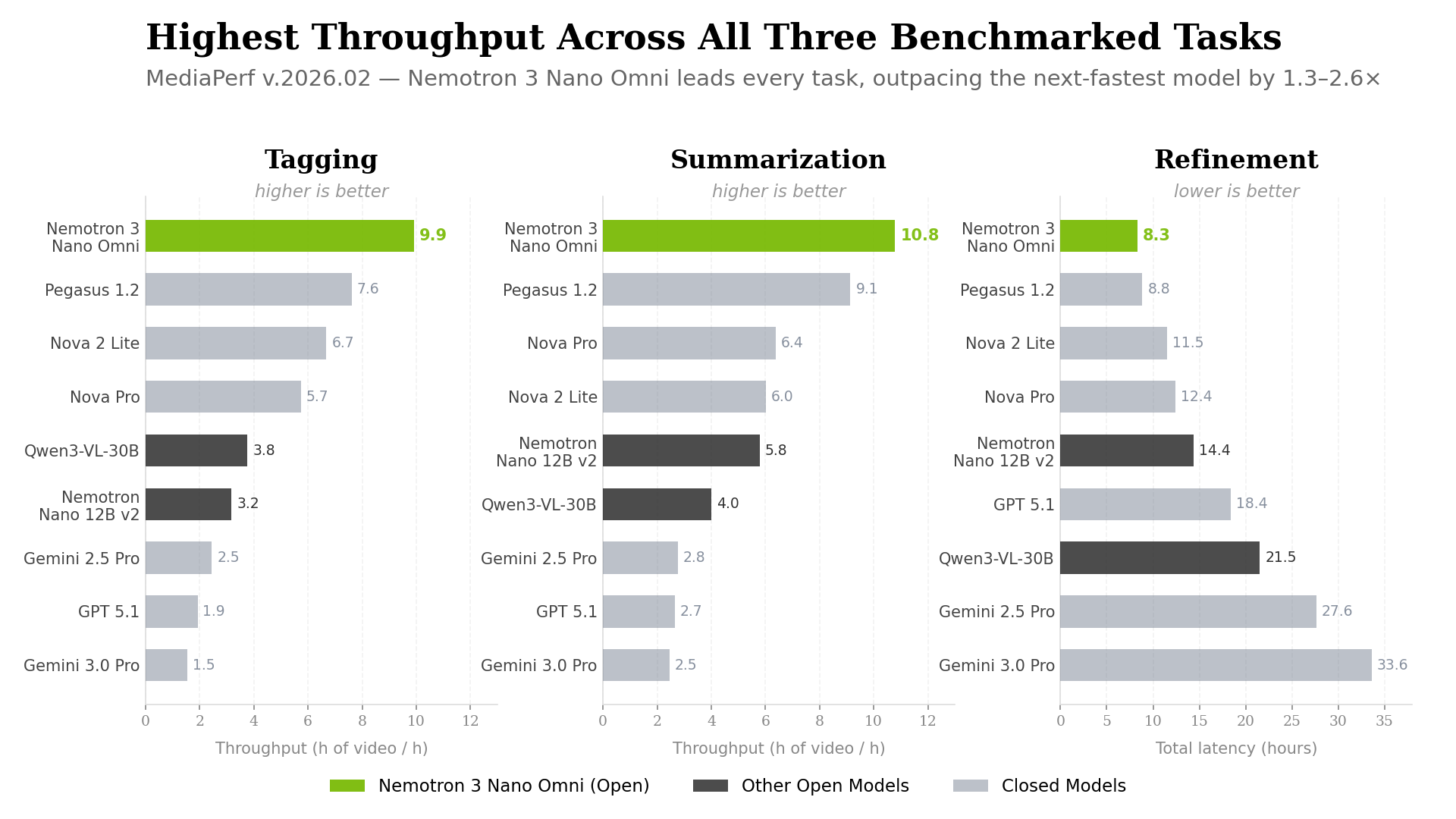
The throughput result extends beyond tagging. Nemotron 3 Nano Omni led throughput on every benchmarked task, across all open and closed-source models:
- Tagging: 9.91 h/h (5× GPT 5.1, 6× Gemini 3.0 Pro, 2.6× Qwen3-VL)
- Summarization: 10.79 h/h (4× GPT 5.1, 4× Gemini 3.0 Pro, 2.7× Qwen3-VL)
- Refinement (5 rounds): 8.30 hours total vs. 18.37h (GPT 5.1), 33.60h (Gemini 3.0 Pro), 21.52h (Qwen3-VL)
The gap is especially visible on the refinement workload. This is the task that most closely mirrors real production workflows: iterative, multi-round, and compounding in cost. Nemotron 3 Nano Omni finishes in 8.30 hours what takes GPT 5.1 more than twice as long and Gemini 3.0 Pro more than four times as long.
On quality, Nemotron 3 Nano Omni matches Qwen3-VL within noise on both tagging F1 and summarization score on MediaPerf’s media-industry workloads, and clearly outperforms the previous Nemotron Nano 12B v2 VL on both tasks.
Why this matters
Throughput at catalog scale
Media companies don’t process a few dozen videos. They process catalogs that span tens of thousands to millions of hours. At that scale, throughput multipliers are not incremental improvements. They are the difference between deployments that finish in weeks and deployments that drag on for months. A model that processes video 3-6× faster than frontier closed-source alternatives fundamentally changes the operational calculus of what’s feasible.
Cost efficiency on the highest-volume task
Video-level tagging is the single highest-volume production task in media AI. It powers content discovery, ad targeting, recommendations, and rights workflows. It’s the workload that runs across your entire catalog, often repeatedly as taxonomies evolve.
Inference cost is the dominant, recurring cost driver across these workloads, and the one that compounds fastest across large catalogs. On this specific task, Nemotron 3 Nano Omni has the lowest inference cost of any benchmarked model, open or closed-source. Being the most cost-efficient model on the most common task is a significant result.
An open model pushing the Pareto frontier
What makes these results especially notable is that this is an open model. Nemotron 3 Nano Omni ships with open weights, open post-training recipes, and open synthetic data. Teams can deploy it anywhere: on-prem, in their own cloud, across a wide range of NVIDIA AI infrastructure including NVIDIA DGX systems to NVIDIA GeForce RTX GPUs.
For organizations that need full deployment control and data sovereignty, having an open model that leads on both throughput and cost efficiency on production media tasks represents a meaningful shift. An open model pushing the Pareto frontier on real-world media workloads is a win for both NVIDIA and the ecosystem.
Why the architecture matters
The efficiency results above aren’t accidental. They’re a direct reflection of how Nemotron 3 Nano Omni is built.
The model uses a 30B-A3B Mixture of Experts (MoE) architecture with a hybrid Transformer-Mamba backbone. At 30 billion total parameters with only 3 billion active per token, the architecture is designed for efficiency at inference time, exactly the kind of sustained, high-throughput processing that catalog-scale video workloads demand.
It is a unified multimodal model: vision, audio, and text are processed within a single reasoning loop rather than through separate model stacks stitched together at the orchestration layer. This eliminates redundant inference passes and context fragmentation across modalities.
For video specifically, the model employs 3D convolution layers (Conv3D) for efficient temporal-spatial processing and Efficient Video Sampling (EVS), which allows it to process longer videos within the same compute envelope, lowering the total cost of inference.
MediaPerf’s results on real media workloads independently show NVIDIA Nemotron 3 Nano Omni is the highest-efficiency open multimodal model.
Get involved
MediaPerf is an open, community-driven effort, shaped by contributions from technical leaders and practitioners across the industry.
Explore the full results
The complete leaderboard, methodology, and evaluation data are available on mediaperf.org. The benchmark codebase is open source under Apache 2.0, and the evaluation data is shared under CC-BY, permitting commercial use for validation, custom evaluation, and fine-tuning. If you have questions about results or methodology, reach out at info@mediaperf.org.
Submit your model
If you’re a model provider and want your model benchmarked on real media workloads, we want to hear from you. Submit models, contribute code or data, or help steer the benchmark by joining our working group or governance board. Email info@mediaperf.org to get started.


