



Smarter Metadata Tagging for the Multimodal Era


One of the biggest challenges in organizing and searching unstructured multimedia data is tagging: assigning meaningful labels that reflect what an image, video, or transcript segment represents. At Coactive, our Dynamic Tags capability has evolved to help organizations flexibly define and robustly apply tags across datasets, without being locked into rigid taxonomies or extensive manual labeling. This helps content-rich organizations find and use their most valuable content faster to improve monetization, reuse, and personalization.
With the latest Dynamic Tags, we’re introducing major advances in how tags are created, trained, scored and previewed. This update brings together new asynchronous workflows, enhanced classifiers, and advanced prompt engineering, making the system more scalable, accurate, and aligned with user intent.
Why Dynamic Tags Matter
A tag is not just a label—it’s an interpretation. “Action” might mean high-speed car chases to one user, while to another it emphasizes close combat scenes. Dynamic Tags allow users to define tags in their own terms, evolve them over time, and apply them seamlessly across multimodal datasets.
Defining tags in a traditional setting is labor-intensive, error prone and costly. It requires defining a tagging schema, careful labeling, quality checks, and domain expertise. Tagging videos is especially hard because they’re long, dynamic, and multimodal; thus, requiring frame-by-frame attention to visuals, audio, and context. With the latest Dynamic Tags, the Coactive team set out to remove these limitations and deliver a more intuitive, multimodal tagging experience.
Core Technical Highlights of Dynamic Tags
Video Native Data Modeling
We redesigned how videos are onboarded and represented, enabling truly native tagging across multiple modalities. Users can define prompts for both visual and transcript content, generating tags at fine-grained levels - video frames, shots, and transcripts - for richer multimodal understanding. The system architecture has been optimized for scalability and visibility, ensuring smooth handling of large datasets.
Prompts Are Key
A big lesson in Dynamic Tags is that tags are only as good as the prompts used to define them.
- Tag name prompts - simple words like “action” or “fantasy.”
- Modality-aware prompts - richer, tailored descriptions for visuals or transcripts.
- LLM-assisted prompts - automatically generated by a language model for the best performance.
The results were clear: well-crafted, modality-aware prompts dramatically improve accuracy because these models work best with descriptive, caption-like inputs - not single words.
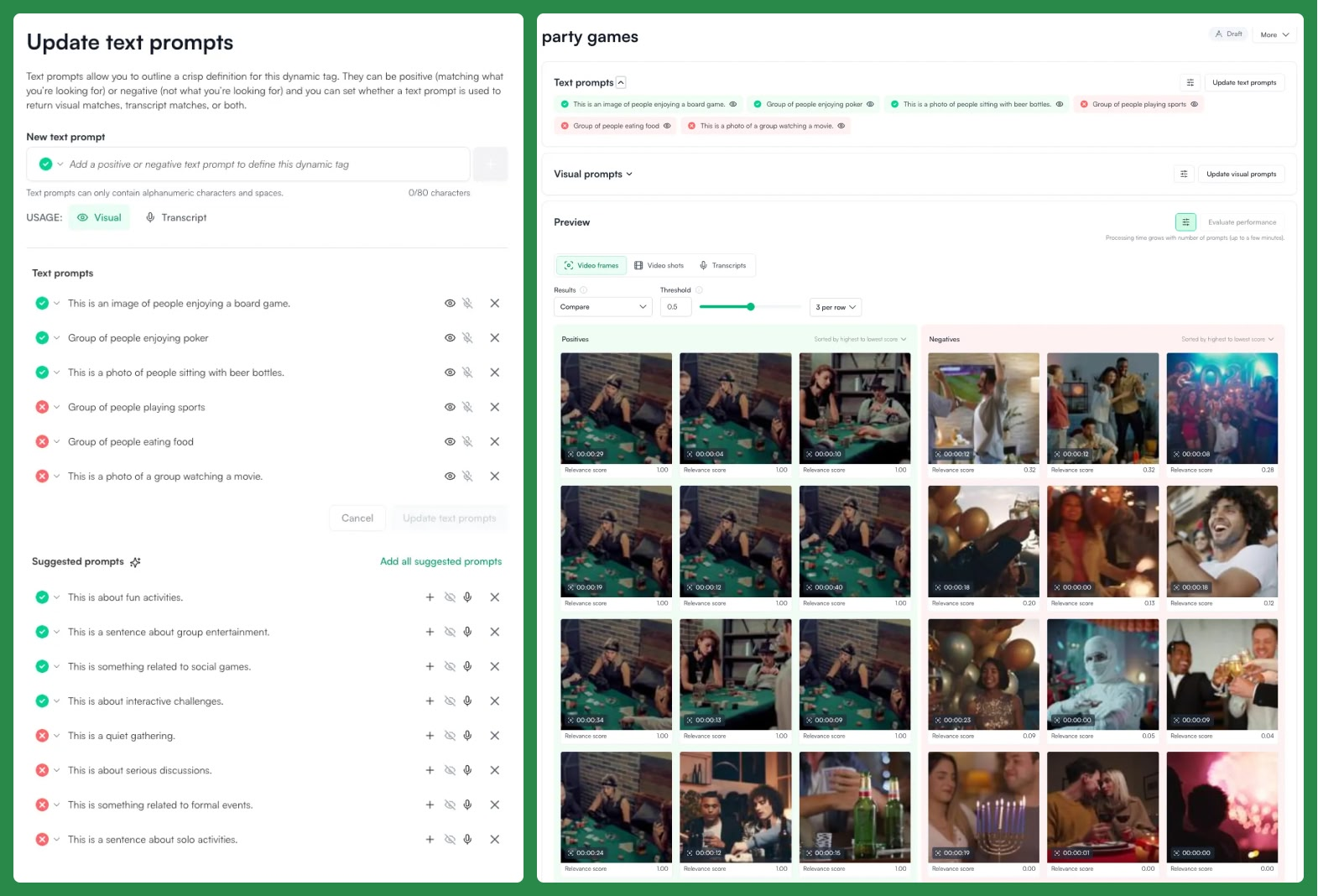
Previews show positively and negatively labeled examples across the full range of relevance scores (0-1), providing immediate and comprehensive feedback on the current tag iteration.
Simple but Smarter Classifier
The heart of Dynamic Tags is an updated lightweight classifier that trains on user-provided text descriptions and any visual examples to estimate relevance scores, enabling accurate tagging even with few prompts.
Real Time Evaluation
Dynamic Tags now provides improved previews, giving users a snapshot of classifier performance through multimodal samples with varying relevance scores. This allows for finer control and faster iteration.
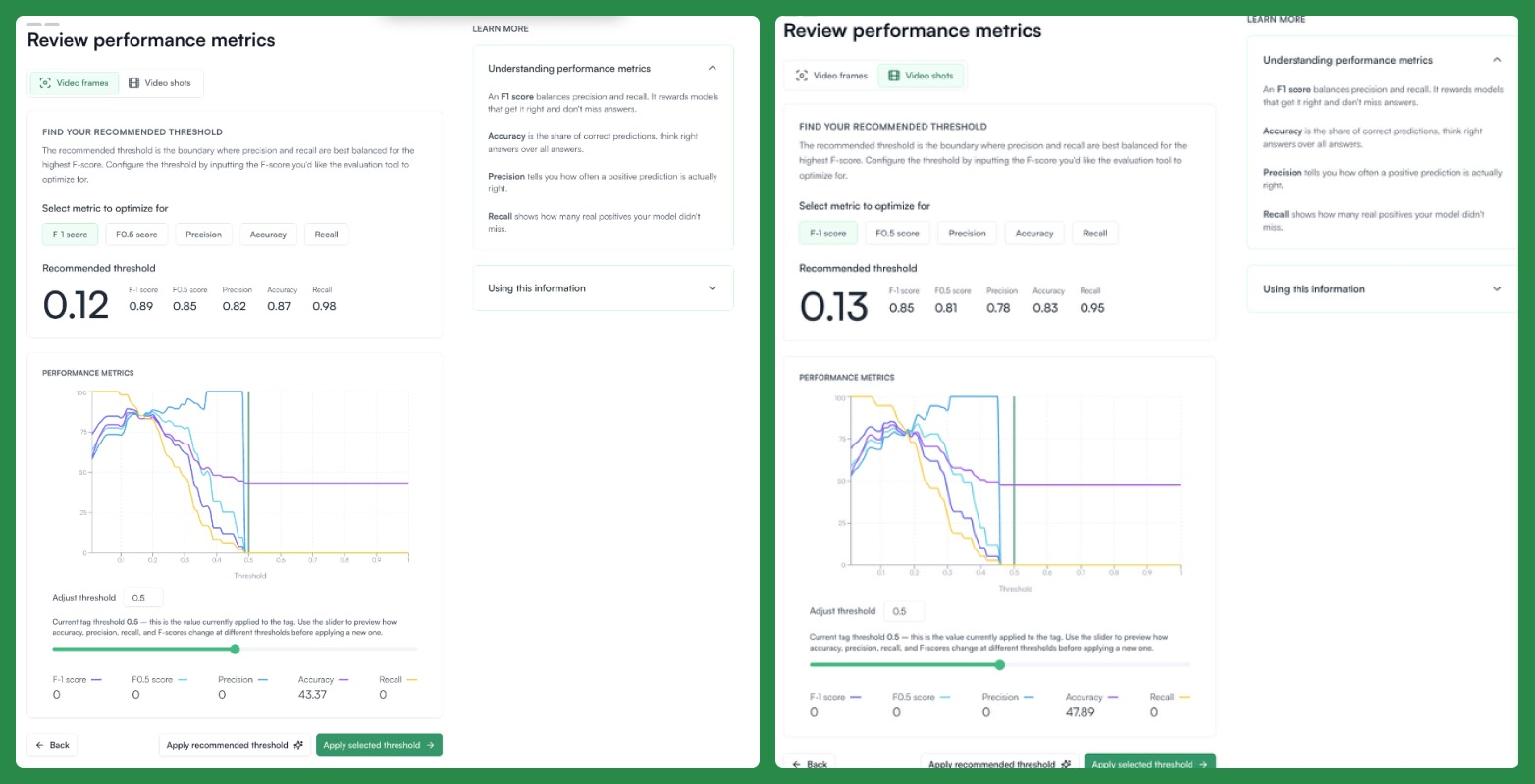
We also introduce an auto-evaluation workflow that generates ground truth and enables users to measure training performance using standard machine learning metrics – F1-score, precision, recall, accuracy – at both frame and shot levels.
New Asynchronous Workflows in the Background
Updated workflows support iterative, real-time tag training without interrupting your workflow. A dedicated background system handles training requests asynchronously - learning from the prompts you provide.
Once satisfied, users can publish their tags to trigger scoring across the entire dataset and, as before, explore and analyze results directly through Coactive’s SQL interface.
Additional new workflows now enable users to logically group tags and apply these groups across multiple datasets, further reducing the manual effort that required defining repetitive tags for similar datasets.
What This Enables in Dynamic Tags
These core technical improvements make tagging more flexible and future-proof. Key capabilities enabled include:
- Modality-Specific Prompts: Tailor prompts for visual or transcript content for higher precision. For best results, make your tags descriptive and modality-aware: use visual features like objects and colors for visual text prompts; use phrases you want to look for in transcript prompts.
- LLM Suggestions: Automatically generate candidate prompts from tag names or user intent.
- Multi-Level Tagging: Generate tags at video frame, video shots and transcript levels for improved control.
- Dataset-Independent Tags: Train on one dataset, apply across others for global inference.
- Draft Mode: Create tags in “draft” mode for quick, iterative refinements before publishing.
- Tag Grouping: Group tags for logical separation of training and application.
- Updated Previews: Deeper, real-time qualitative insights into tag performance.
- Tag Evaluation: Measure performance of trained tags to gauge if further tuning is required and offer quantitative and actionable insight into tags.
What We Learned While Building Dynamic Tags
Developing the latest Dynamic Tags reinforced key lessons:
- Prompt design > model tuning. Foundation models perform best when inputs mirror their training data.
- Decoupling training from scoring solved scalability issues by allowing millions of tag probabilities to update without downtime.
- Incremental retraining means we no longer need to retrain everything when a prompt changes.
- Interpretability matters. More fine-grained visibility such as previews and evaluation enable better decision-making.
- LLM-generated prompts reduce guesswork and provide users with clear examples of how to effectively prompt the model for a tag, aligning inputs with model expectations.
- Robust systems engineering: Handling challenges like data schema migrations and multimodal aggregation consistency ensures that new features integrate seamlessly with existing datasets and workflows.
Continuing to Support What Works from Previous Versions
Dynamic Tags retains and improves core capabilities:
- Metadata Enrichment: Automatically generate rich metadata for videos and images without manual tagging.
- Rapid Classification: Classify content from keyword lists with minimal human review needed.
- No-Code Model Tuning: Teach the system by searching, tagging, or reviewing results.
- Flexibility and Customization: Define tags for mood detection, brand safety, ad targeting, and compliance, all tailored to your enterprise needs.
Conclusion: The Future of Metadata Tagging
Dynamic Tags represents a significant leap forward in making tagging scalable, accurate, and user-centric. By combining:
- Asynchronous workflows for training and scoring,
- Lightweight classifier for text and visual prompts, and
- Intentional, modality-aware prompting for higher accuracy,
We’ve created a system that works to align with user intent.
Dynamic Tags is not just a new version — it’s a smarter way to discover, organize, and understand your multimedia content.
Get in touch with the Coactive team to learn how you can get the most out of your content with Dynamic Tags.


