



Achieve Advanced Content Intelligence with Amazon Nova Multimodal Embeddings and Coactive AI

.webp)
In today’s media-rich ecosystems, content intelligence refers to the process of transforming unstructured assets (videos, images, audio, and documents) into machine-interpretable signals that power search, recommendation, analytics, compliance, and monetization workflows. Whereas you may have just started with a video filename and a title, content intelligence helps systems understand the who, what, when of an asset like a full-length movie, down to the moment-by-moment level and with the rich detail that can power new use cases. Teams employ a wide range of techniques to achieve this, from simple text-based proxies to fully native multimodal video models. Each approach comes with trade-offs across quality, speed, operational complexity, and cost, which means no single method is optimal for every scenario.
With a platform like Coactive AI, you can enable all three levels of content intelligence within a single system: Level 1 text proxies, Level 2 multimodal fusion, and Level 3 native multimodal embeddings, so that teams can choose the right approach based on the use case, content type, and budget. This flexibility is especially powerful as organizations scale, allowing them to start with lightweight representations and seamlessly adopt deeper multimodal understanding as precision needs evolve.
Modern multimodal embedding models, such as Amazon Nova Multimodal Embeddings, represent a significant step forward in the native multimodal and video landscape. Rather than treating each modality as its own pipeline, these models consolidate semantic meaning into a single high-dimensional vector. By jointly reasoning over text, images, documents, audio, and video, they capture complex concepts such as actions, relationships, temporal patterns, and scene context with remarkable precision.
This post explores the three levels of content intelligence, highlights real-world use cases where these approaches matter most, and outlines how developers can implement fusion or native multimodal embedding pipelines in practice.
Overview of Content Intelligence Approaches
Content intelligence techniques generally fall into three progressively more capable levels, each offering increased fidelity at higher computational cost.
Level 1: Text Proxy Generation
At the foundational level, media is converted into textual representations (summaries, transcripts, OCR outputs, and descriptions), which then serve as stand-ins for the original content. Because text is inexpensive to generate and easy to index, this approach offers an attractive balance between cost and utility.
However, text-only proxies inherently ignore visual and auditory cues. They cannot capture actions (e.g., handshakes, explosions, car crashes), scene changes (e.g., moving from a street scene to a courtroom), visual style, or non-verbal events (e.g., smiles, tears, nods). For large libraries with low per-asset ROI, such as archives, back catalogs, or news footage, Level 1 provides a scalable entry point since it is affordable and fast, but it offers limited semantic depth.
Levels of Content Intelligence
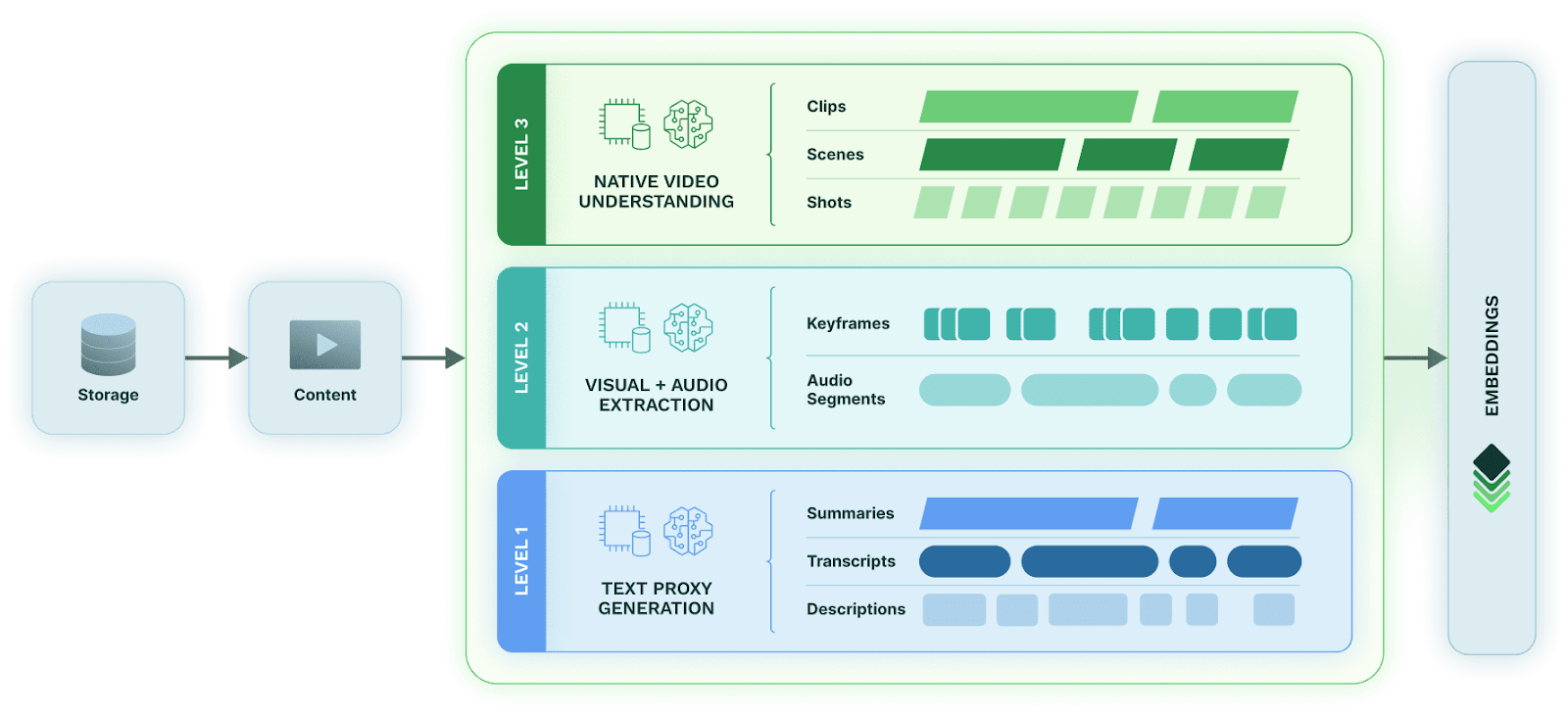
Level 2: Visual + Audio Extraction (Multimodal Fusion)
At the next level, teams extract features directly from individual modalities using specialized models, for example, keyframe-based image embeddings or short-form audio embeddings. These modality-specific signals are then fused using heuristics or learned weighting schemes.
This approach offers deeper semantic coverage than text proxies alone and allows developers to isolate or compare information across modalities. This means that it can power far more powerful use cases than Level 1, such as content personalization or contextual advertising. This increased accuracy does require a deeper investment, since it requires greater processing power and complexity, and that processing does require more time to complete. However, companies making the investment here often see much greater benefits.
On the technical side, fusion approaches introduce their own operational overhead: coordinating pipelines, normalizing outputs, reconciling modality conflicts, and maintaining custom post-processing logic. While more accurate than Level 1, these systems grow increasingly complex as use cases evolve.
Level 3: Native Video Understanding
The most advanced category integrates all modalities within a single, natively multimodal model. Models like Amazon Nova Multimodal process video, audio, imagery, and text jointly, producing a unified embedding that encodes both spatial and temporal semantics.
This paradigm unlocks capabilities that are difficult or impossible with fusion-based systems:
- Rich, natural-language queries that capture subtle constraints
- Retrieval that accounts for both context and sequence
- Robustness across multiple versions or edits of the same content
- Minimal downstream business logic
Instead of piecing together multiple signals and filtering large candidate sets, developers rely solely on the model’s unified representation and trade control for simplicity.
Although these levels differ significantly in cost, complexity, and capability, they are not mutually exclusive. Different teams and different stages of a workflow may require different levels of understanding.
Use Cases Across Advertising, Media Measurement, Fan Engagement, and Social Platforms
The practical impact of choosing between Level 1, Level 2, and Level 3 becomes especially clear in real-world media applications.
Advertising and Creative Analysis
Consider this light hearted commercial that depicts a Trojan horse waiting at the gates in a Bronze Age landscape, only to reveal that the ad is actually for a cybersecurity product.
- Level 1 (text proxies) might accurately capture the spoken script but completely miss the visual metaphor, making it difficult to classify or retrieve based on the creative concept.
- Level 2 (visual + audio fusion) can detect horses, castles, and armor, and can combine those signals with transcripts, but doing so requires additional logic to connect the dots.
- Level 3 (native video models) understands the full scene holistically, recognizing the visual reference, the narrative context, and the cybersecurity theme in a single embedding.
This richer understanding translates to more accurate creative classification, contextual ad matching, brand safety analysis, and content-based targeting.
Media Measurement and A/B Testing
Advertisers often test subtle variations of the same creative, one with a male versus female voiceover, minor changes in background audio, or a dog swapped for a cat in the final scene. To measure real performance differences, systems must reliably distinguish between these variants.
Whereas this is challenging to do with other methods, a native video model makes these distinctions trivial to identify. It encodes the differences naturally within the embedding space, enabling accurate grouping, deduplication, and comparative analytics without elaborate rule sets or custom heuristics.
Fan Engagement and Moment Discovery
Entertainment and sports organizations frequently need to surface highly specific moments: a surprise guest joining an artist on stage, a decisive game-winning play, or a player’s signature celebration. These moments are often visually or audibly subtle and may appear across many nearly identical performances or broadcasts. For example, during Beyoncé’s Cowboy Carter tour, Jay-Z made a surprise appearance during the song “Crazy in Love.” Distinguishing that exact moment from countless other tour stops, rehearsals, or past performances would be impossible with Level 1 text-only understanding and extremely challenging with Level 2 multimodal fusion, which would require complex logic to reconcile audio, visual, and temporal cues.
Native video models excel here. They capture temporal structure, actions, interactions, and transitions natively, making it easy to retrieve the precise clip where the moment occurs, even across thousands of hours of content.
Social Media Search and Remix Culture
Finally, social platforms deal with enormous variation: reposts, remixes, overdubs, cropped videos, mashups, and countless user edits. Searching through all of that content to find specific clips is challenging. Identifying the viral clip where BTS’ J Hope dances to Kendrick Lamar’s “Not Like Us,” for example, requires simultaneously understanding who appears on screen and which song is playing in the audio track. Level 1 text proxies miss this entirely, and Level 2 multimodal fusion struggles to unify these signals without custom logic.
A native video model can reason over these combined signals directly, enabling precise retrieval even when the content has been heavily remixed, altered, or recontextualized.
Developing Multimodal Fusion and Multimodal Embedding Systems in Practice
When building real-world content intelligence systems, developers typically choose between two architectural patterns: multimodal fusion pipelines (Level 2) and native multimodal embedding pipelines (Level 3). Each offers different advantages, trade-offs, and implementation paths, and both can be the right tool depending on the use case.
Multimodal Fusion (Level 2): Fine-Grained Control Across Modalities
In multimodal fusion systems, each modality (text, audio, and visuals) is processed through its own foundation model. Queries are run through these models independently, producing modality-specific embeddings that are searched against separate indexes. The results are then merged and reranked using custom logic that reflects the application’s needs.
Multimodal Fusion Pipeline
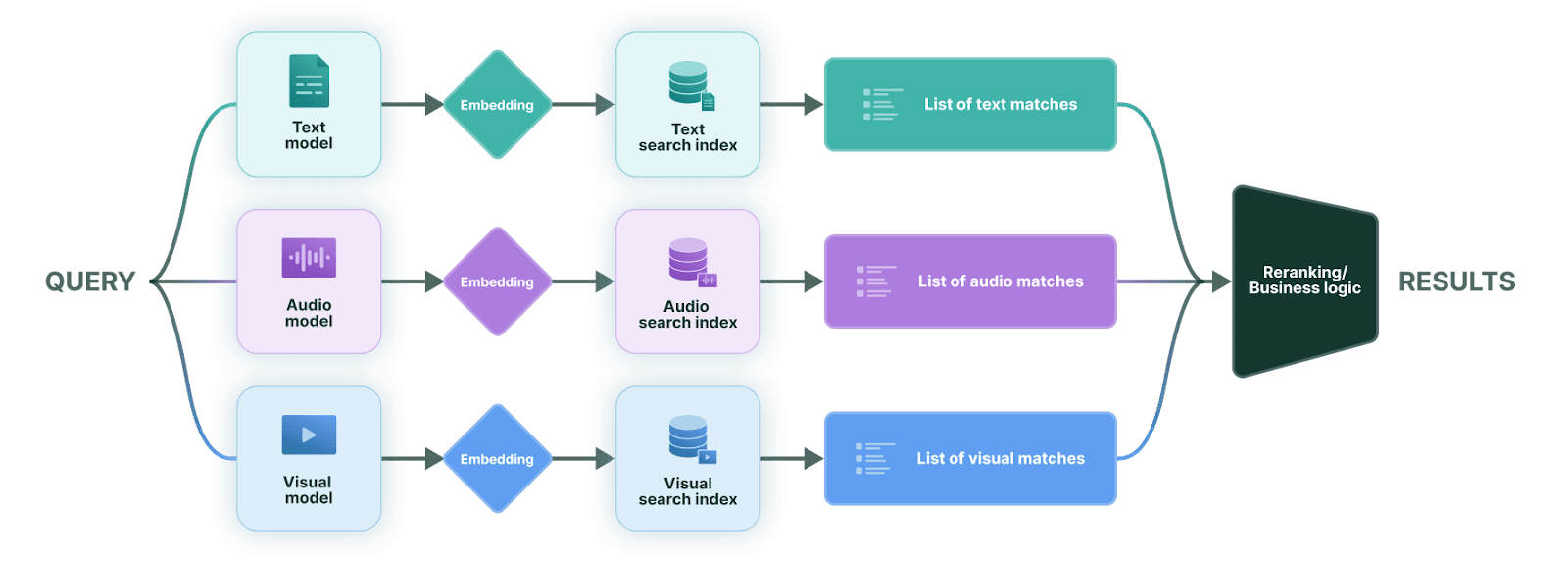
This architecture introduces more moving parts, but it provides something extremely valuable: precise control over how each modality contributes to relevance.
This is particularly important in enterprise environments, where different teams care deeply about the distinction between what is said and what appears on screen. For example:
- Media and broadcast organizations may require strong visual detection signals to ensure that an object or topic is physically present rather than simply referenced in narration.
- Marketing, celebrity analytics, and brand safety teams often need to confirm that a specific person appears in the frame, not merely mentioned in the talk track.
- Newsrooms and editorial pipelines may prioritize on-screen facts over commentary to avoid conflating descriptive narration with actual content.
Because each modality remains isolated until the final stage, developers can apply modality-specific thresholds, weighting rules, and filters. This makes fusion pipelines especially powerful for compliance-sensitive, editorially controlled, or deterministic workflows.
The trade-off is operational complexity: multiple models, multiple indexes, and a reranking layer that must be maintained and tuned over time.
Native Multimodal Embeddings (Level 3): More Expressive Queries, Simpler Systems
Native multimodal models such as Amazon Nova Multimodal consolidate all modalities into a single embedding, eliminating the need for modality-specific query paths or fusion logic. The model jointly interprets text, images, audio, and video, capturing their interactions and temporal structure directly.
Multimodal Embedding Pipeline
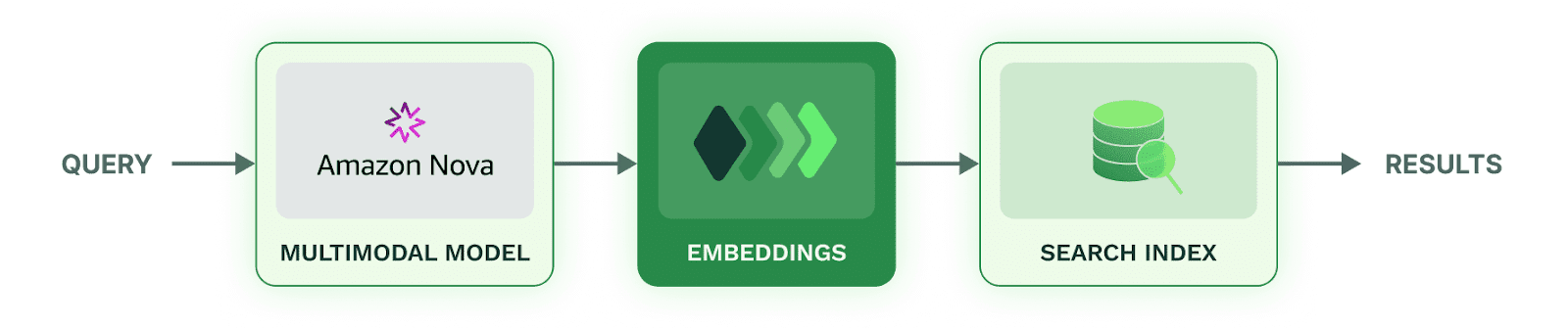
This simplifies the developer experience in the following ways:
- One model to run and scale
- One embedding representation to store
- One search index to query
- No modality-specific reranking or heuristics
These systems are ideal for applications where users want to express rich, natural-language queries and where meaning emerges from the interplay between audio and visual context. Native embeddings offer powerful out-of-the-box relevance and reduce the overhead of maintaining custom logic.
Practical Considerations for Choosing Between Levels of Content Intelligence
So which level of content intelligence do you need? From an implementation standpoint:
- Choose Level 2 (fusion) when you need:
- strict separation or weighting of modalities
- deterministic or rule-based logic
- enterprise-grade editorial control
- guaranteed prioritization of on-screen facts over narration or vice versa
- Choose Level 3 (native embeddings) when you want:
- simplified system architecture
- holistic interpretation of multimodal signals
- ability to express complex or subtle queries naturally
- high-quality retrieval without extensive tuning
In many production environments, teams ultimately use a hybrid of both native embeddings for broad semantic retrieval and fusion pipelines for verification, filtering, or compliance workflows that require explicit modality control.
Need the Best Content Intelligence? Pick AWS and Coactive AI
While the three levels of content intelligence differ significantly in cost, complexity, and precision, they do not have to be mutually exclusive. Coactive AI makes it easy to adopt any of these content intelligence approaches, or combine them, within a single platform, allowing teams to start with the most cost-effective methods and scale into deeper multimodal understanding as use cases evolve.
Combined with advanced models like Amazon Nova Multimodal Embeddings, organizations can unlock powerful new capabilities across advertising, media measurement, fan engagement, and social platforms, while keeping their infrastructure consistent, flexible, and future-proof.
Get in touch to learn how you can integrate Coactive and Amazon Nova Multimodal Embeddings into your workflows today.


.webp)