Open catalog, ready to use
Access a growing library of hosted open-source and proprietary models, all pre-integrated and ready for deployment.


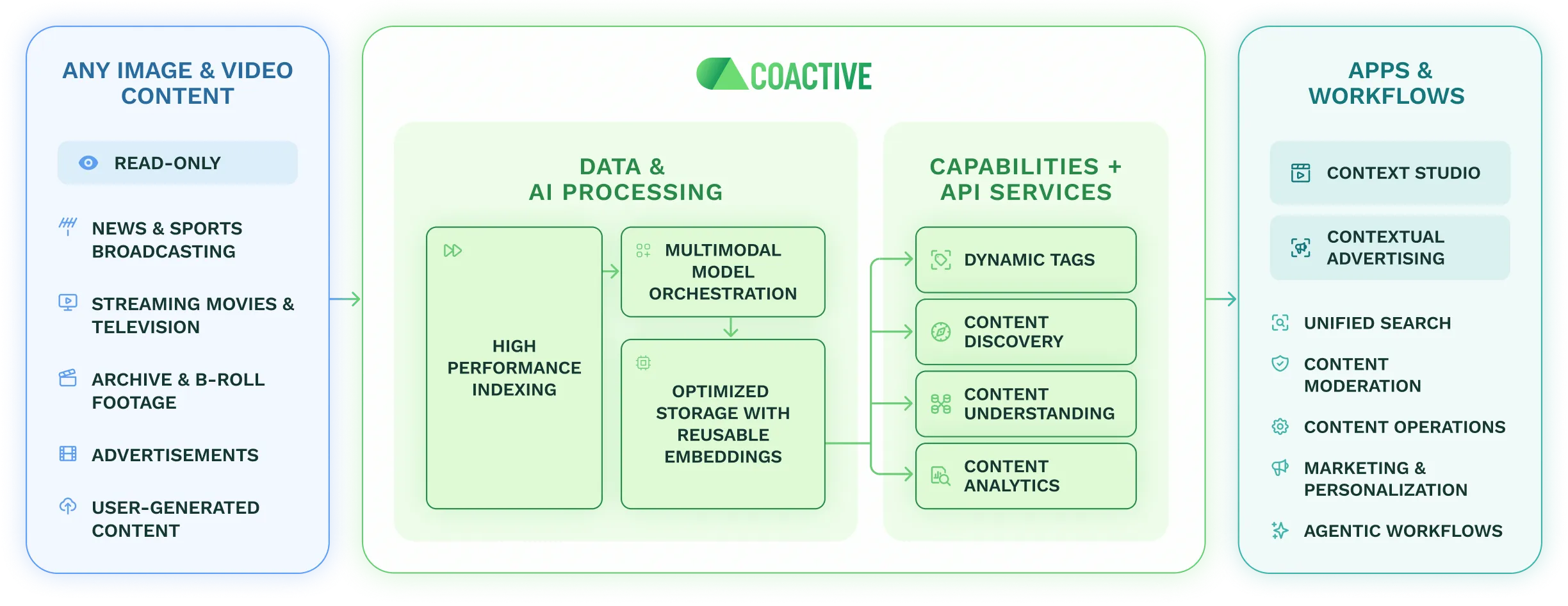
A full-stack platform for Contextual Intelligence: purpose-built for the scale, precision, and control that modern media demands. Ingest once. Power every downstream application from a single intelligence layer.




Ingest your content once. Every downstream application (contextual advertising, content discovery, analytics, moderation) draws from the same unified intelligence layer. No reprocessing. No redundancy.

Your intent-based classification system. Bring your own taxonomy, brand standards, or advertiser brief. The platform scores every moment against your definitions across visual and transcript signals.
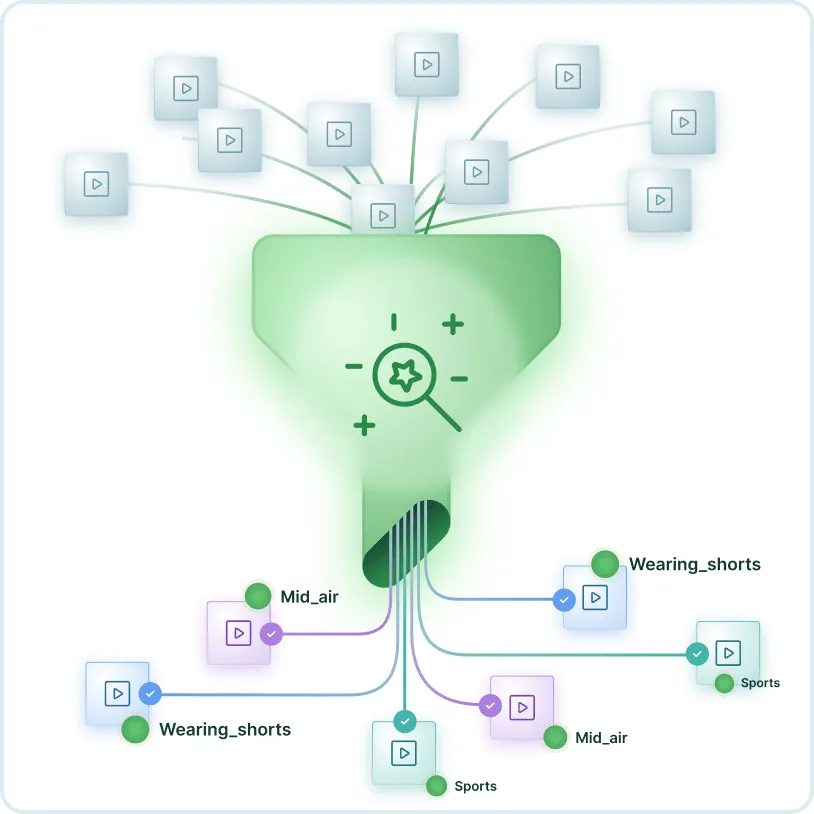
Tag any moment with natural-language prompts, from shot-level to video-level precision.
Start zero-shot. Refine with a few examples. No model training required.
The result is a durable, queryable intelligence layer that powers downstream applications from contextual advertising to content analytics.
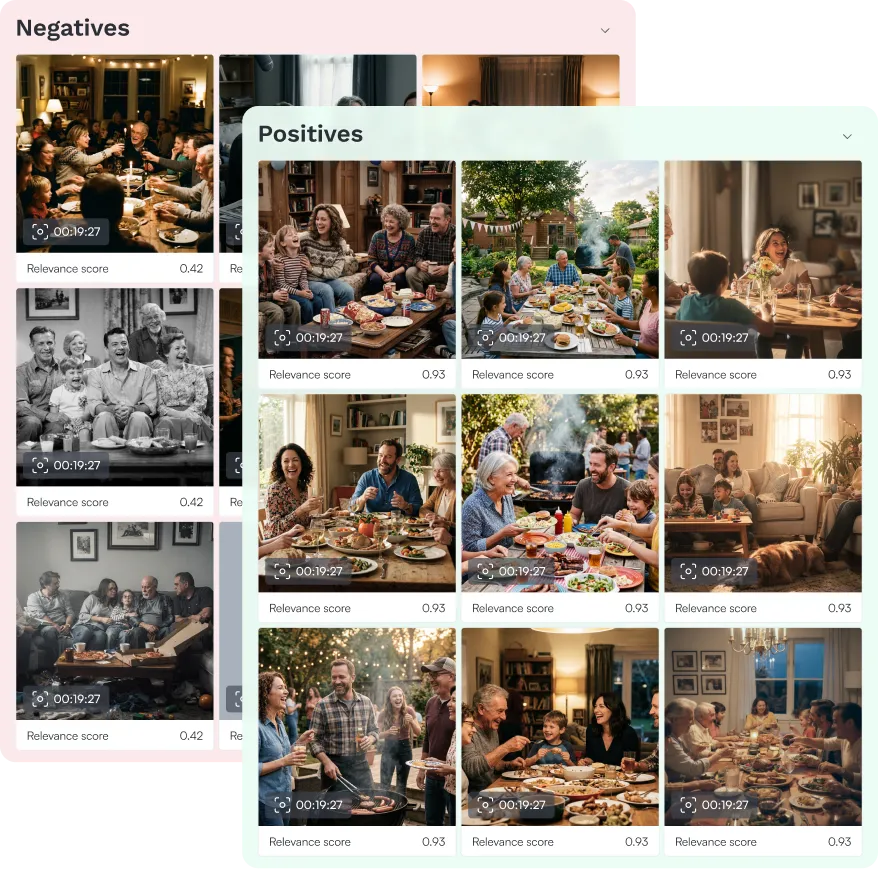
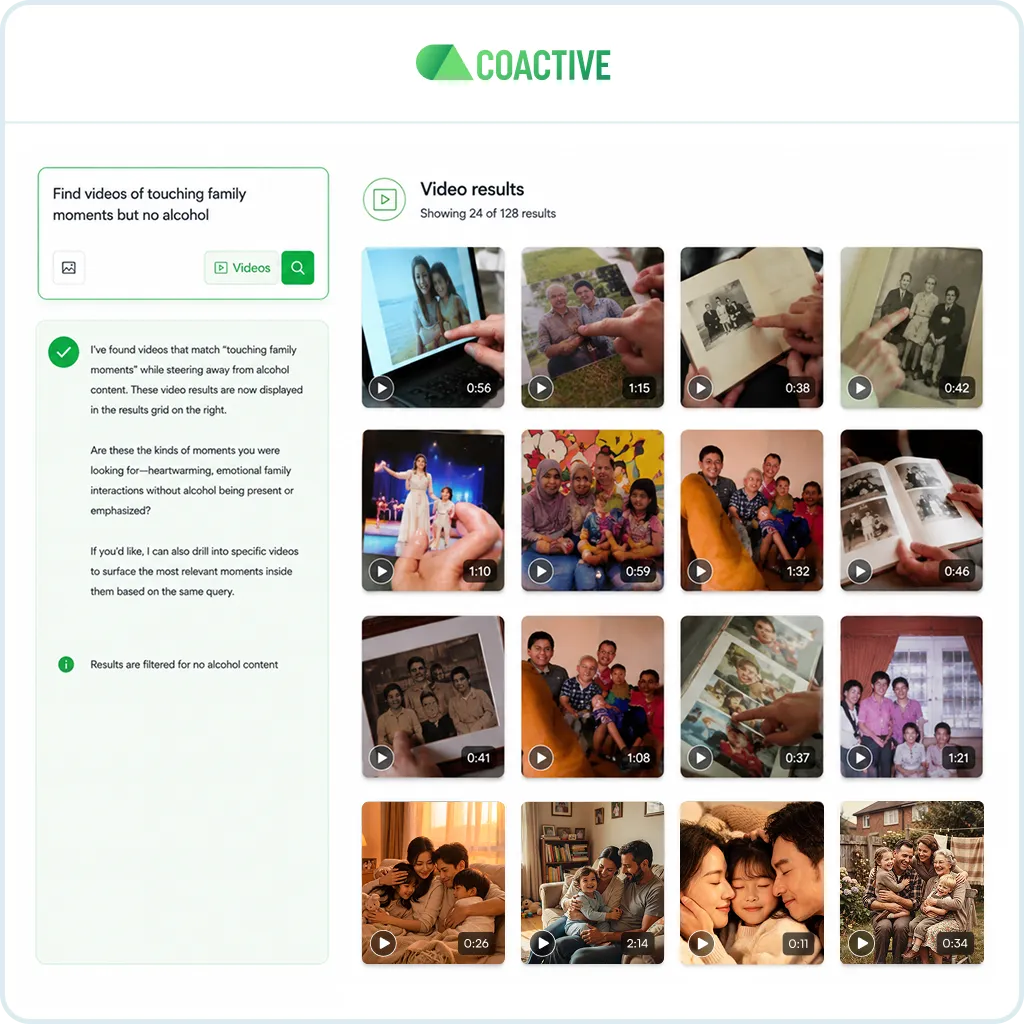
Agentic and semantic search across your image and video libraries. Describe what you're looking for. The platform interprets your intent and surfaces the most relevant results.
Search across images and videos in a conversational query. Drill into any video to find the exact shots that match.
Search by transcript (semantic or exact match), by image, or by what you want to exclude.
Everything available programmatically through a REST API for teams building their own experiences.
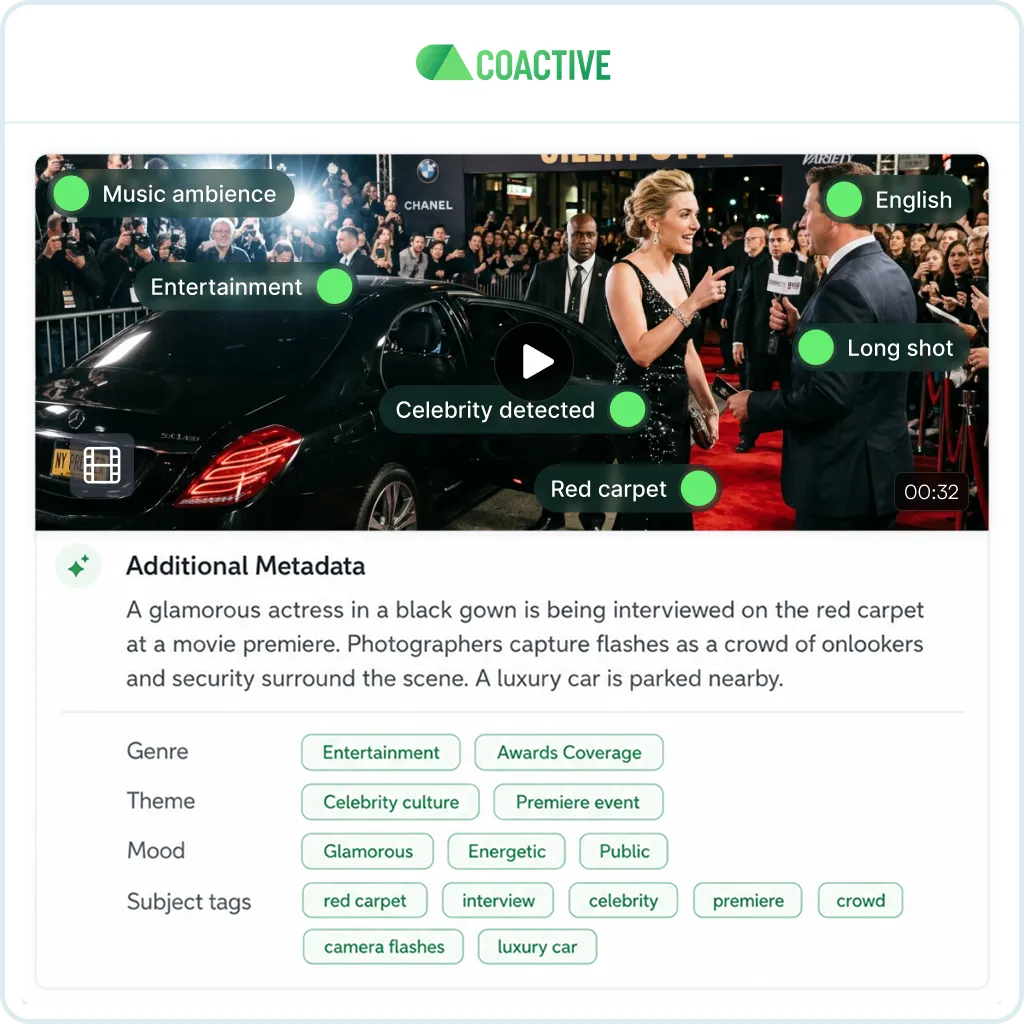
The platform's detection and recognition layer. Structured intelligence generated from your content from day one, before you define a single custom tag.
Celebrity Detection identifies who's on screen. Concepts classifies visual patterns from labeled examples.
Narrative Metadata describes genre, mood, subject, and format at the video level.
All outputs feed into Dynamic Tags, Content Discovery, and Content Analytics as a shared foundation.
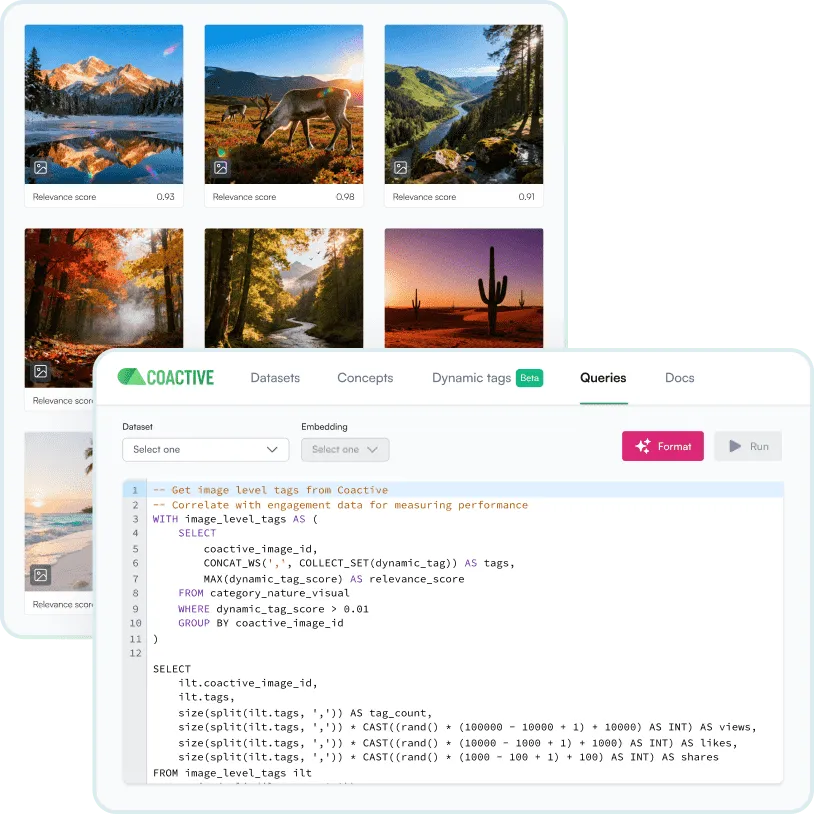
Your content library as a structured data asset. The platform automatically organizes intelligence into a media data model that mirrors how content is produced and consumed.
CA structured table hierarchy (video, scene, shot, moment, transcript) with tag scores, metadata, and concept probabilities at every level.
Query everything in SQL. Filter, aggregate, and join across the full content hierarchy.
Export to external analytics environments, data warehouses, and BI tools through the API.

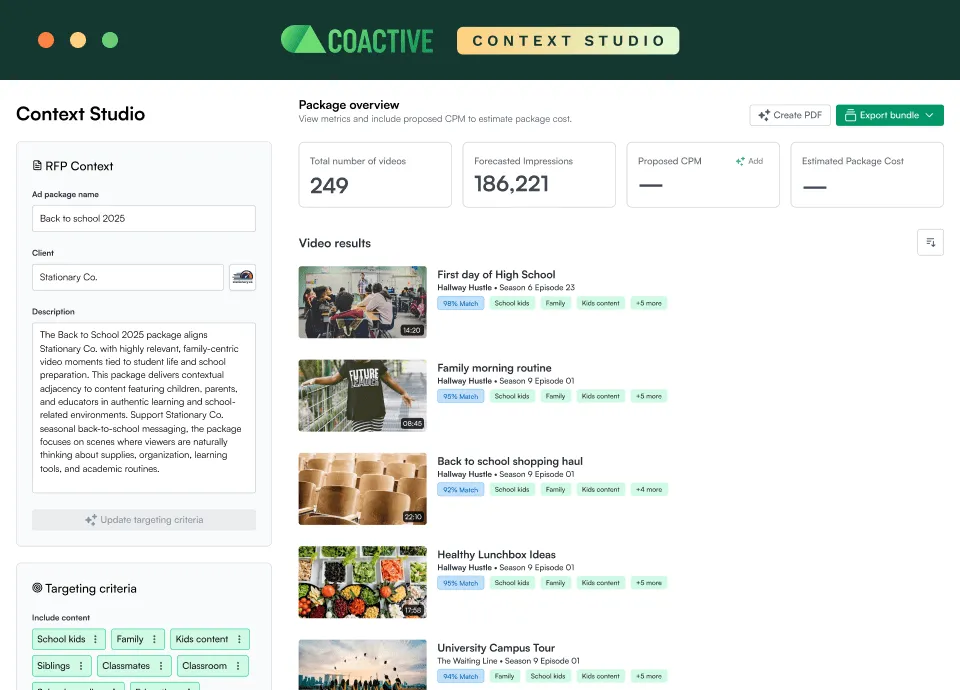
Context Studio orchestrates Dynamic Tags, Content Discovery, and Content Understanding into a complete workflow, from advertiser brief to activation-ready packages. No code required.
Best for: ad sales teams, campaign planners, and media operations teams.

Use Dynamic Tags, Content Discovery, and Content Analytics directly through the platform UI. Define your own classifications, search your library, and query your intelligence layer in SQL. Export to external analytics environments and data warehouses.
Best for: content operations, data science, and editorial teams.

Access every capability programmatically through REST APIs. Embed Coactive intelligence into third-party tools like Mimir and Adobe Premiere, connect to data warehouses and BI platforms, or build entirely custom applications on the intelligence layer.
Best for: product & engineering teams, data partners, and technical integrators.
Coactive sits above the foundation-model layer rather than locked to any one model. Bring your own, chain several together, and keep your embeddings, tags, and evaluations intact as models evolve, so today’s work keeps paying off as the field moves.
Access a growing library of hosted open-source and proprietary models, all pre-integrated and ready for deployment.
Integrate your preferred closed or fine-tuned models through frameworks like AWS Bedrock, Azure AI, and Databricks. Maintain full control over what runs where.
Design flexible inference pathways by chaining models together. For example, run lightweight captioning first, then escalate to deeper multimodal analysis only when needed.
Our optimized platform handles massive scale at speed. Reusable embeddings minimize long-term compute and storage costs.
Handle massive volumes of media—one customer was able to ingest up to 2,000 video hours per hour while reducing costs by 30–60% compared to traditional pipelines.*
Reusable embeddings minimize long-term compute and storage costs: reuse them across use cases with no duplicate ingestion or compute, for lower TCO.
Unlike other platforms and cloud providers, you can fine-tune repeatedly using stored embeddings: no per-run pricing or forced reprocessing.
*Based on an actual customer experience. Ingestion performance is dependent on specific conditions, and your experience may vary.